
Introduction
Over the last several years, the stealer ecosystem has evolved in several aspects, from the malware families to the platforms used. Close to a year ago, we began monitoring several of these platforms and building a system to ingest the data shared in the hopes of helping the victims. We've shared this data with Have I Been Pwned, aiming to help the victims of infostealers.
Designing Our System
When we designed our system, we wanted to build a competitor to the largest threat intelligence platforms. We aimed to capture as much unique data as possible and achieve as close to real-time alerting as possible. We wanted to monitor the following sources for differing reasons, as they all provided value.
- Telegram: One of the primary data drivers within the stealer log ecosystem. Contributed Millions of unique credentials at its peak within a single day.
- Forums: These often included file-sharing links, including, but not limited to, combolists, stealer logs, or database dumps.
- Social Media Sites: Provided data sources we may have missed, often Telegram links to other groups or channels that shared combo lists or stealer logs.
- Tor Network: Concluded that we did not want to scrape due to a lack of data.
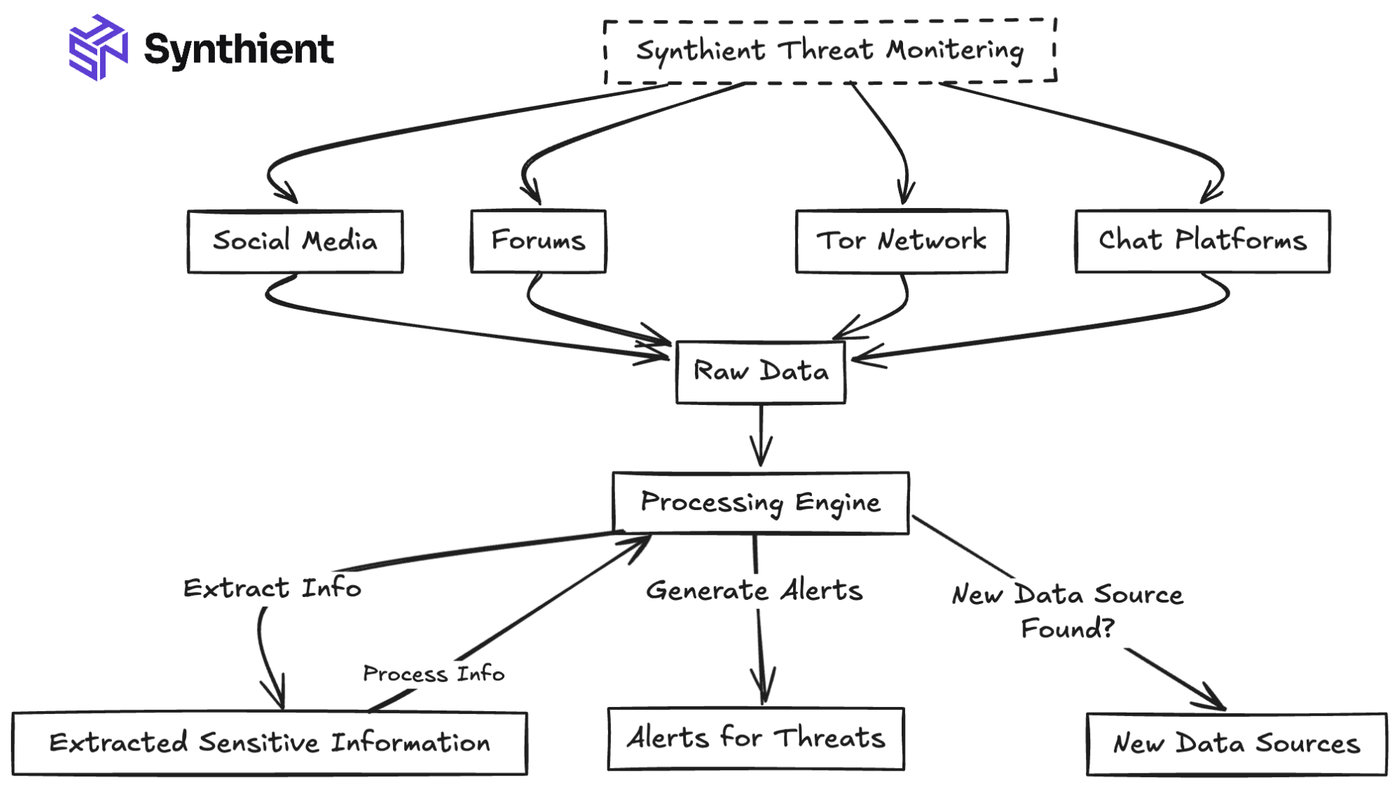
Fig 1: An early prototype of the initial project
We would discover that Telegram was the largest data driver, with a single Telegram account able to ingest as many as 50 million credentials in a single day. For this reason we will focus this blogpost on Telegram and less on the other platforms.
Crawling Telegram
Before we discuss the technical details of building our system, we must provide some background on the stealer scene itself, which is critical to understanding the design decisions made.
Understanding the Stealer Log Ecosystem
The stealer log ecosystem is split into multiple different groups, with the main ones being:
- Primary Sellers: Responsible for managing key operations, often operate a public channel in which stealer logs are shared,, and maintaining a paid private channel in which clients can buy access to.
- Aggregators: They aggregate the stealer logs and often share them on their public channel. They usually provide clients with the ability to search for victims on specific sites using the aggregated data they've acquired.
- Traffers: Not directly responsible for selling logs; however, they are responsible for spreading malware in cooperation with primary sellers. Will occasionally have their own channel on which data is sent as proof.
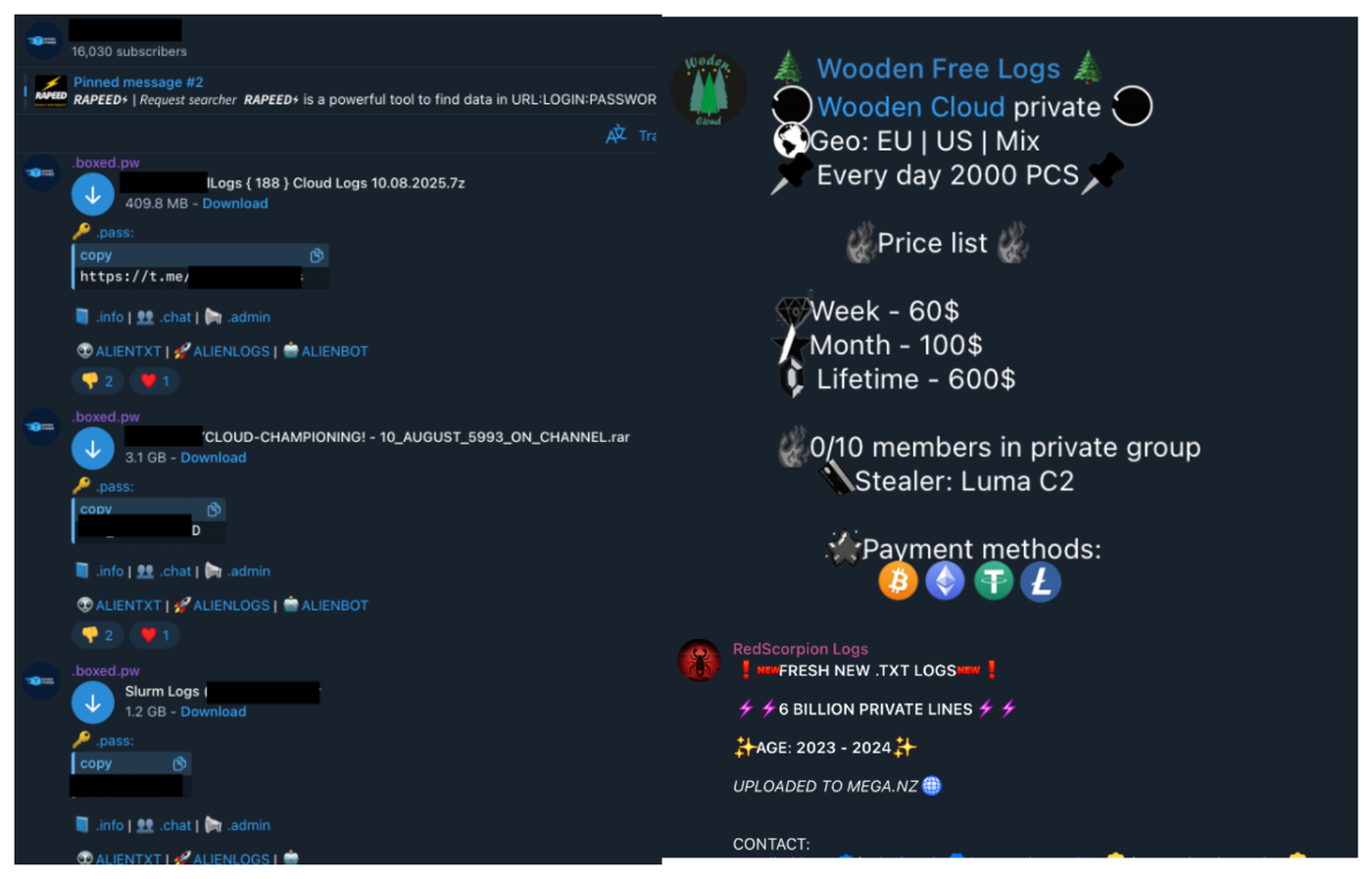
Fig 2: Seller and reseller ecosystem
The motivations of aggregators differs from primary sellers with aggregators often leaking data in an attempt to gain attention. For this reason it is beneficial to monitor not just the primary channels but also the secondary aggregator ecosystem.
Furthermore, the data shared among all these groups differ drastically. Not only will aggregators often repost data from resellers, but they might also merge it with multiple other files to create a pseudo-unique abomination. Combine this with the fact that traffers often use various types of malware, resulting in a unique range of formats.
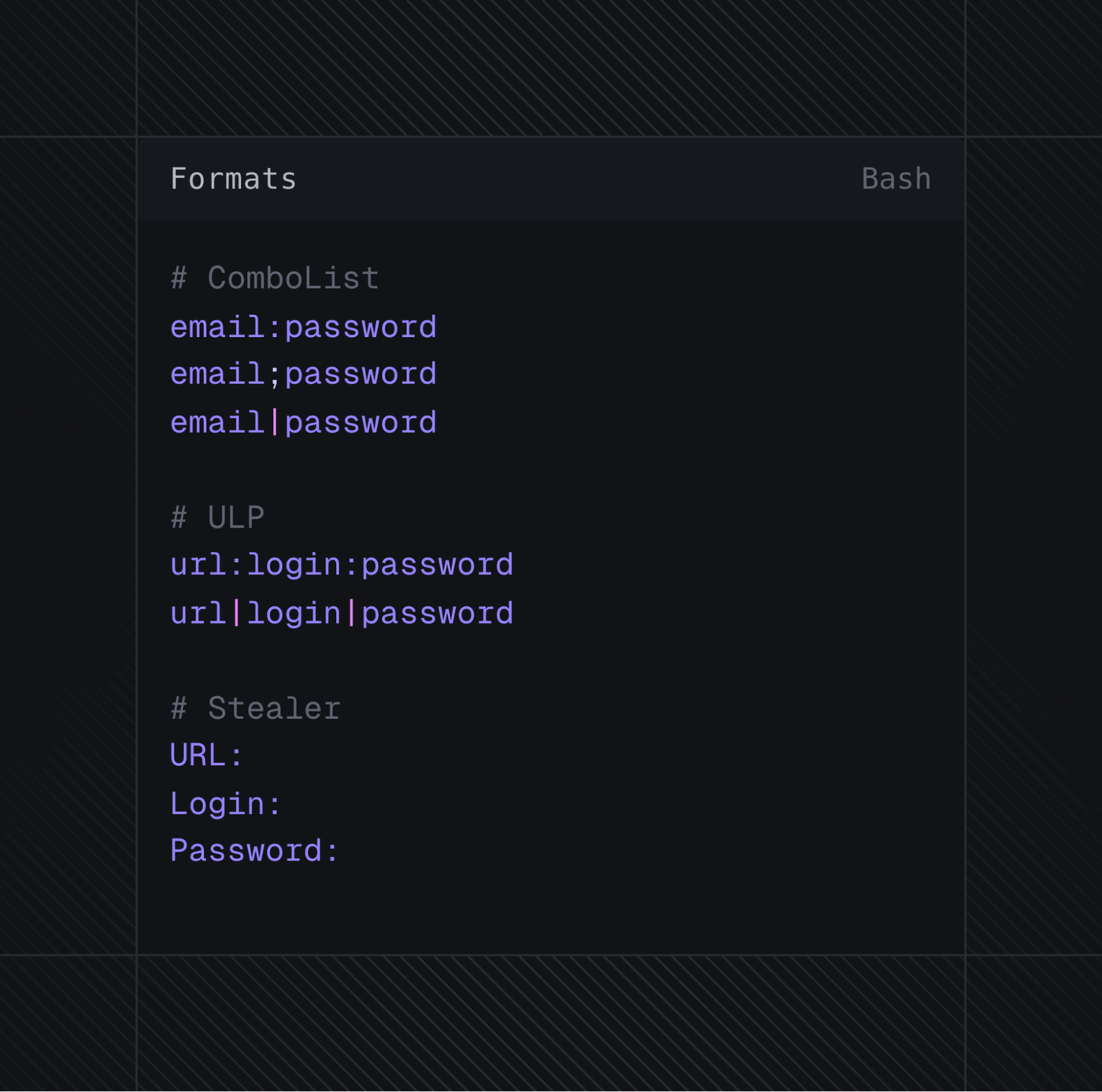
Fig 3. Everyone has their own format and no one’s consistent
Often, primary sellers don't want the aggregators reselling or taking credit for their data directly, so they password-protect the archives with a link to their channel. This can create notable challenges depending on the order in which messages are sent, requiring the messages and the archive to be tracked.
Building Our System
Telegram uses its own MTProto wire format, which allows for interacting with the platform through its bots API. Even though they make it quite straightforward, many of the open-source libraries we looked at either lacked the functionality we required or were no longer actively maintained. We eventually created our own fork from an existing fork of Pyrogram that would support the full functionality of what we needed.
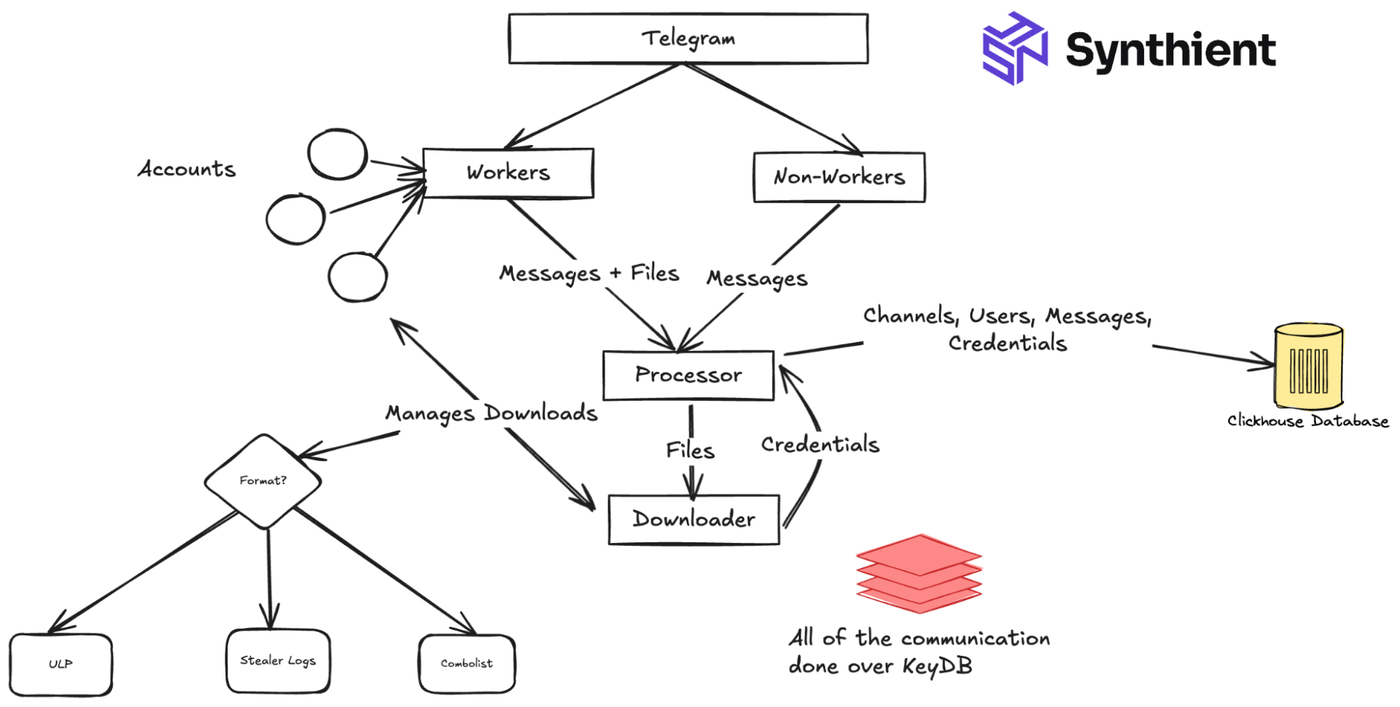
Fig 4. Designing our telegram crawler
We would eventually use around ~20 Telegram accounts, all with Telegram Premium, which we will refer to as workers. Their sole purpose was to either monitor or scrape channels.
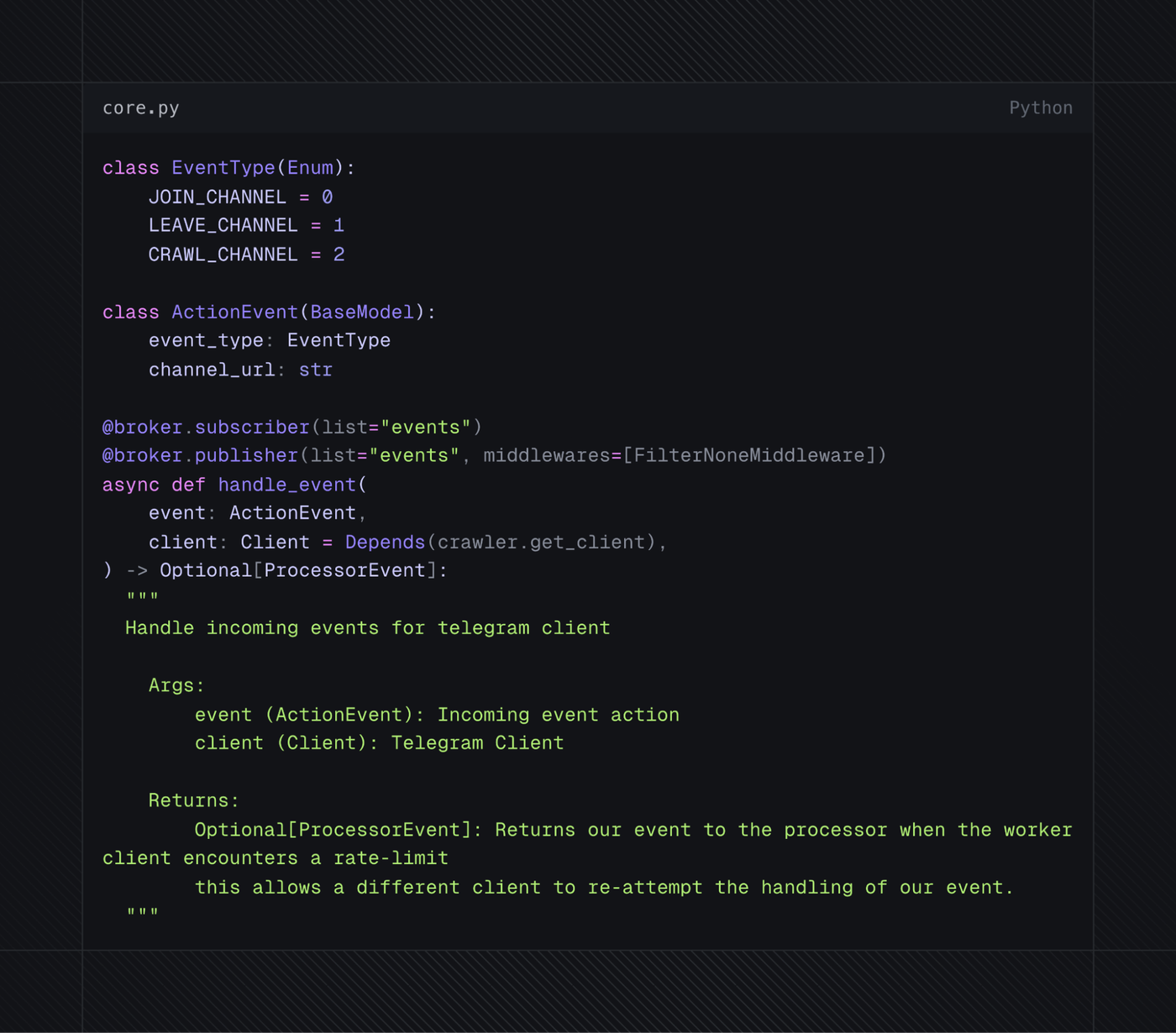
Fig 5. Telegram worker base
If the processor deemed a channel to be associated with stolen data, it would instruct the worker to join the channel. Workers who joined channels would initiate a message listener to forward incoming messages to the processor.
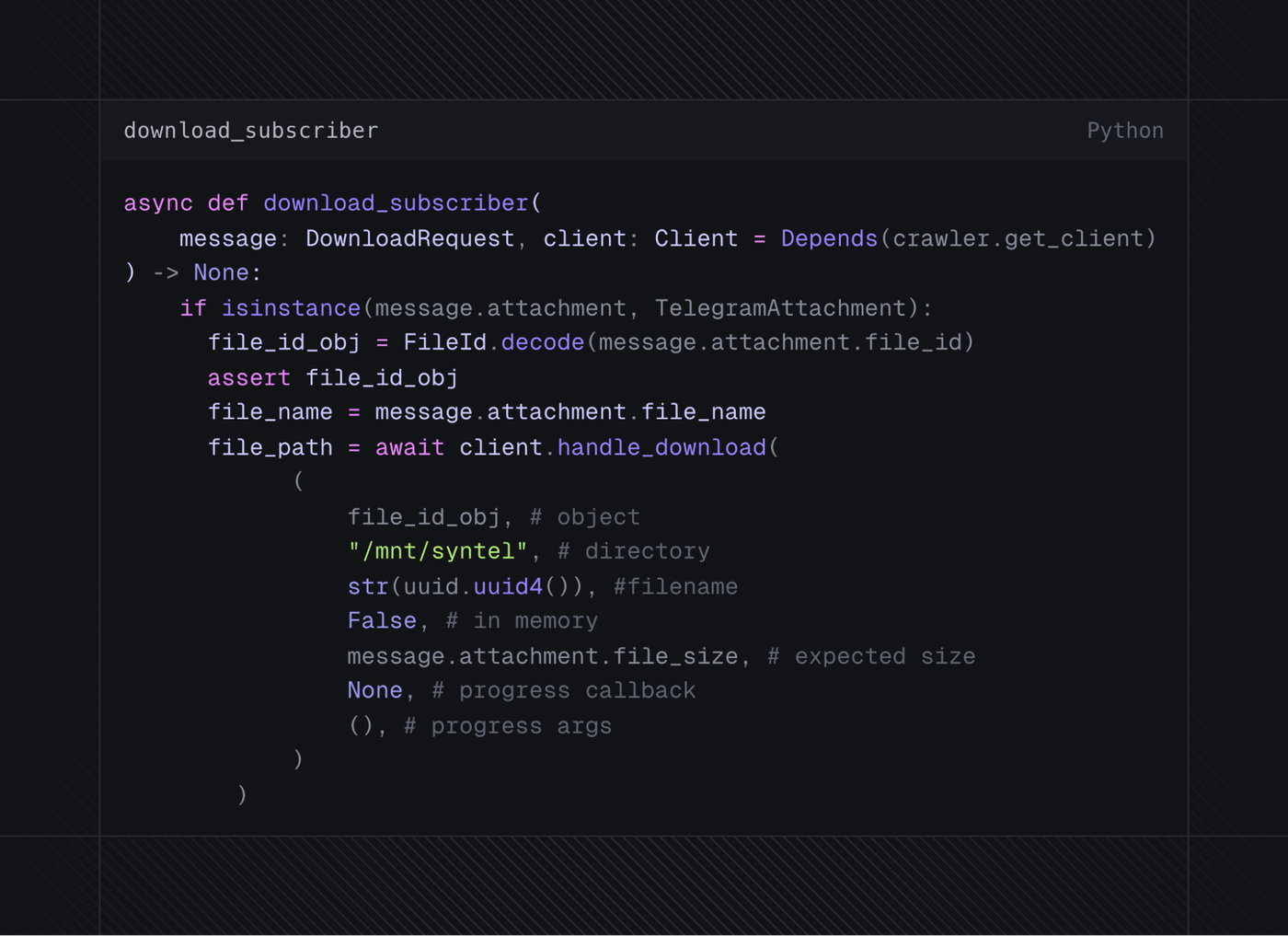
Fig 5. Download subscriber pseudocode
The processor would inspect the messages to extract further unique Telegram join channel or group invite links, sort through messages for attachments, and forward attachments to the decoupled downloading engine for extraction and processing. These messages would be batch-inserted into ClickHouse and any alerts for impacted client assets.
One of the core components of this entire system was the downloader, which is essentially a decoupled worker. We didn't want workers to handle the logic of processing the data since it would impact code quality and create significant performance drawbacks. To account for this, we would authenticate these accounts for a second time, using the new session file to manage a unique worker whose sole purpose was downloading and ingesting the data from files. The downloader would inspect the file, determine the format, and proceed to parse the data from it. Once the downloader ingested the file, it would be deleted to make space for new data, whether it was successfully processed or not.
Handling Duplicate Data
One of the inherent challenges with handling this much data at scale is the volume of duplicate data. Often, the same or similar files are shared across channels hundreds of times within a week. Deduplication would be handled twice: once by checking the file's FileHash on Telegram before downloading and a second time by Clickhouse using ReplacingMergeTree, assuming the file was in an archive.
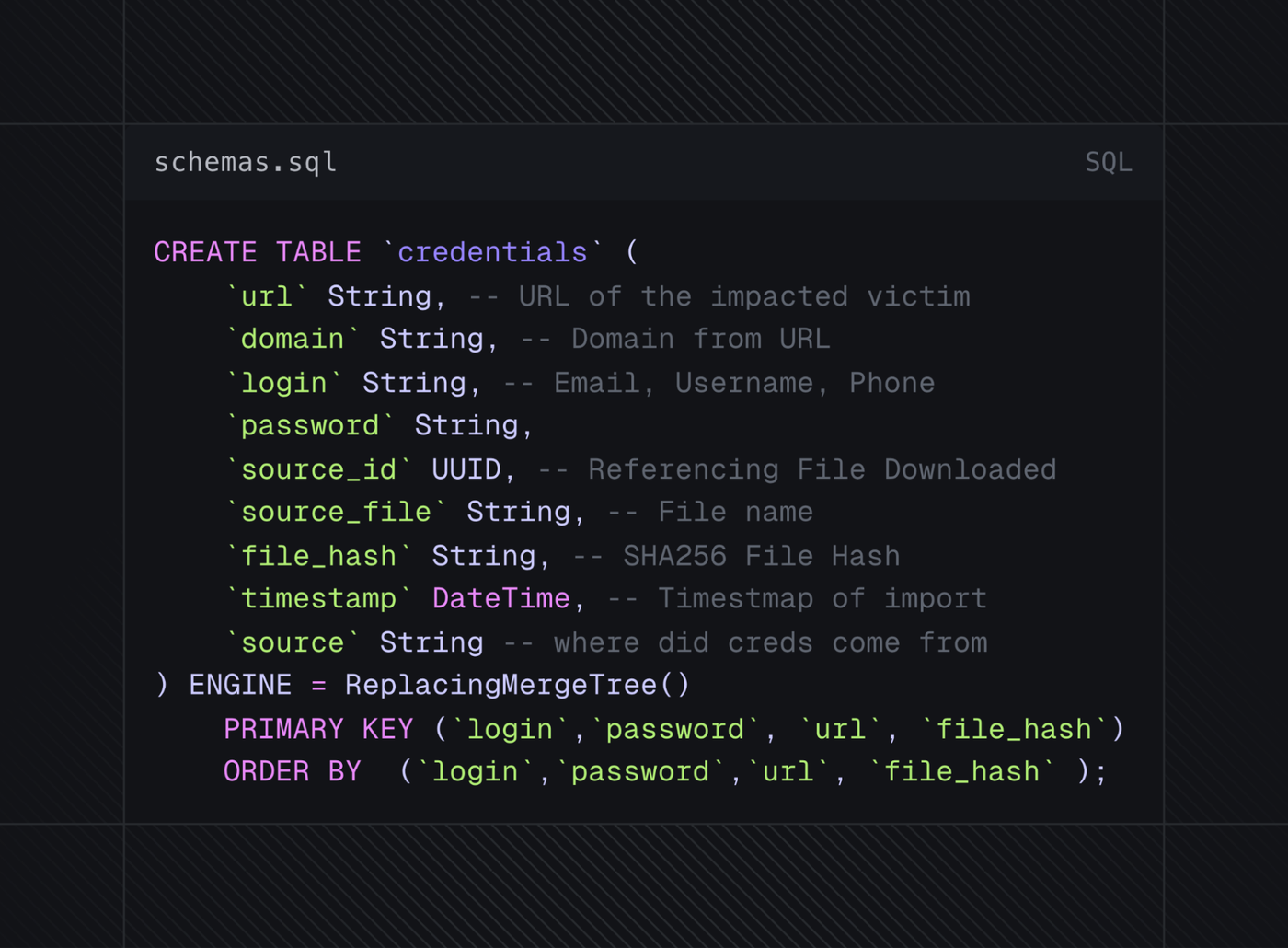
Fig 6. A simplified version of the schemas
We made a conscious decision to also track the file_hash and use that as part of our primary key because we wanted to be able to track how distributed certain credentials are.
Finding Malicious Channels
The goal of this project was to focus on malicious adversary infrastructure. This was achieved by taking a base case of known malicious Telegram channels, which would be scraped to find referencing channels. The more malicious channels that pointed to an unclassified channel, the higher the likelihood that it would be ranked as malicious and crawled.
Conclusion
When we first started this project, we had no idea how much data we would process. It quickly became apparent that we had neither the time nor the resources to continue, which is why we’ve donated the data to Have I Been Pwned. Several platforms in the cybersecurity space allow anyone with a credit card to register on their platform and access victim details without any sort of KYC or background check. Our hope with providing this dataset to Have I Been Pwned is that the victims can properly secure themselves without being double victimized.
Final Stats
- Telegram messages indexed: 30billion
- Credentials Parsed: 80billion
- Peak credentials parsed in a single day: 600million
- Peak messages indexed in a single day: 1.2billion